חוקרים מאוניברסיטת קורנל פיתחו ממשק EchoSpeech לזיהוי דיבור שקט.
משקפי EchoSpeech מצוידים בזוג מיקרופונים ורמקולים קטנים יותר מהמחק בקצה העיפרון ואינם משתמשים במצלמה. המכשיר שולח וקולט גלים אקוסטיים המעידים על שינויים בדינמיקה של שרירי הפנים והפה. אלגוריתם למידה עמוקה מנתח את פרופילי ההד הללו בזמן אמת בדיוק של כ-95%.
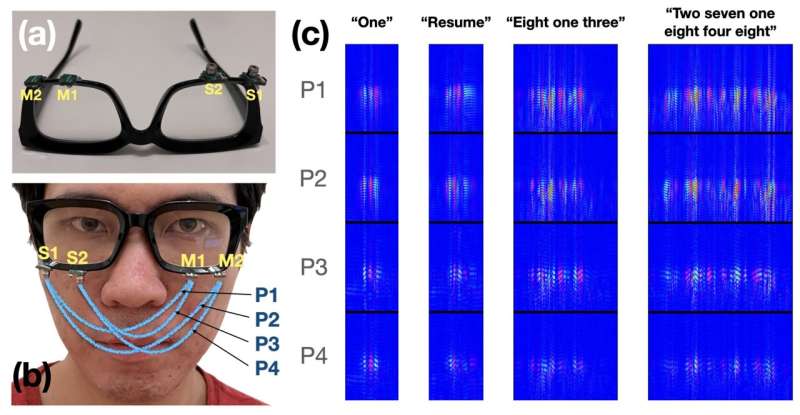 איך EchoSpeech עובד. תמונה: Ruidong Zhang et al.
איך EchoSpeech עובד. תמונה: Ruidong Zhang et al.
הנתונים המתקבלים מועברים באמצעות Bluetooth אלבזמן אמת בסמארטפון, מעובדים ומאוחסנים באופן מקומי במכשיר. המפתחים מדווחים כי ל-EchoSpeech לוקח כמה דקות להתאמן עבור משתמש מסוים.
עבור אנשים שאינם יכולים לדבר, טכנולוגיית דיבור שקט זו יכולה להיות סינתיסייזר קולי נהדר. היא יכולה להחזיר למטופלים את קולם.
Ruidong Zhang, מחבר שותף של הפיתוח
רוב טכנולוגיות זיהוי הדיבור השקטמוגבלים לקבוצה נבחרת של פקודות מוגדרות מראש ומחייבות את המשתמש והאדם איתו הם מדברים להסתכל לתוך המצלמה או לענוד אותה. זה מסבך באופן משמעותי את האפשרות להשתמש במכשירים כאלה. בנוסף, זרם נתונים גדול דורש עיבוד בענן, מה שפוגע בפרטיות המשתמש.
בצורתו הנוכחית, EchoSpeech יכולהשתמש כדי לתקשר עם אחרים באמצעות הטלפון החכם שלך במקומות שבהם הדיבור אינו נוח או לא הולם, כגון במסעדה רועשת או בספרייה שקטה. ניתן לשלב את ממשק הדיבור השקט גם עם סטיילוס ותוכנת עיצוב כמו CAD, ולמעשה מבטל את הצורך במקלדת ועכבר, מוסיפים המפתחים.
קרא עוד:
מדענים הבינו את טיבם של אותות רדיו מוזרים מכוכב הלכת הדומה לכדור הארץ
הילה אדומה התלקחה מעל איטליה. כעת הוסבר טבעו
ווב מצא את החור השחור העתיק ביותר ביקום