コーネル大学の研究者は、静かな音声を認識するための EchoSpeech インターフェイスを開発しました。
EchoSpeech メガネには一対のマイクと鉛筆の先の消しゴムよりも小さく、カメラを使用しないスピーカー。このデバイスは、顔の筋肉と口のダイナミクスの変化を示す音波を送信および受信します。深層学習アルゴリズムは、これらのエコー プロファイルを約 95% の精度でリアルタイムに分析します。
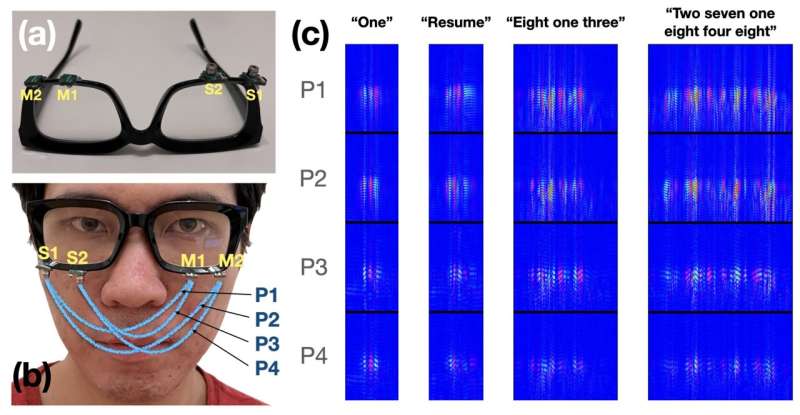 EchoSpeech の仕組み。画像: Ruidong Zhang 他
EchoSpeech の仕組み。画像: Ruidong Zhang 他
受信したデータはBluetooth経由で送信されます。スマートフォン上でリアルタイムに処理され、デバイス上でローカルに保存されます。開発者らは、EchoSpeech が特定のユーザー向けにトレーニングするのに数分かかると報告しています。
話すことができない人にとって、このサイレントスピーチ技術は優れた音声合成装置となります。彼女は患者の声を取り戻すことができます。
Ruidong Zhang、開発の共著者
ほとんどの無音音声認識テクノロジー事前定義されたコマンドの選択セットに限定されており、ユーザーと他の人の両方がカメラを覗き込むか、カメラを装着する必要があります。これにより、そのようなデバイスを使用する可能性が大幅に複雑になります。さらに、大規模なデータ ストリームをクラウドで処理する必要があるため、ユーザーのプライバシーが侵害されます。
現在の形式では、EchoSpeech は次のことができます。騒がしいレストランや静かな図書館など、話すことが不便または不適切な場所で、スマートフォンを介して他の人とコミュニケーションするために使用します。サイレントスピーチインターフェイスはスタイラスやCADなどの設計ソフトウェアと組み合わせることができ、事実上キーボードやマウスの必要性がなくなると開発者らは付け加えた。
続きを読む:
科学者たちは、地球に似た惑星からの奇妙な電波信号の性質を解明しました
赤い光輪がイタリア上空で燃え上がりました。今、その性質が説明されています
ウェッブが宇宙最古のブラックホールを発見