マイクロソフトは人工知能 VALL-E を導入しました。に基づいて音声録音を生成できます。
コーネル大学の研究者VALL-E モデルを使用して音声生成のメカニズムを分析しました。彼らの研究では、プレプリントがarXivサーバーで公開されており、科学者は60,000時間の英語音声に基づいて訓練されたニューラルネットワークを調べています.これは、既存のアナログの数百倍です。
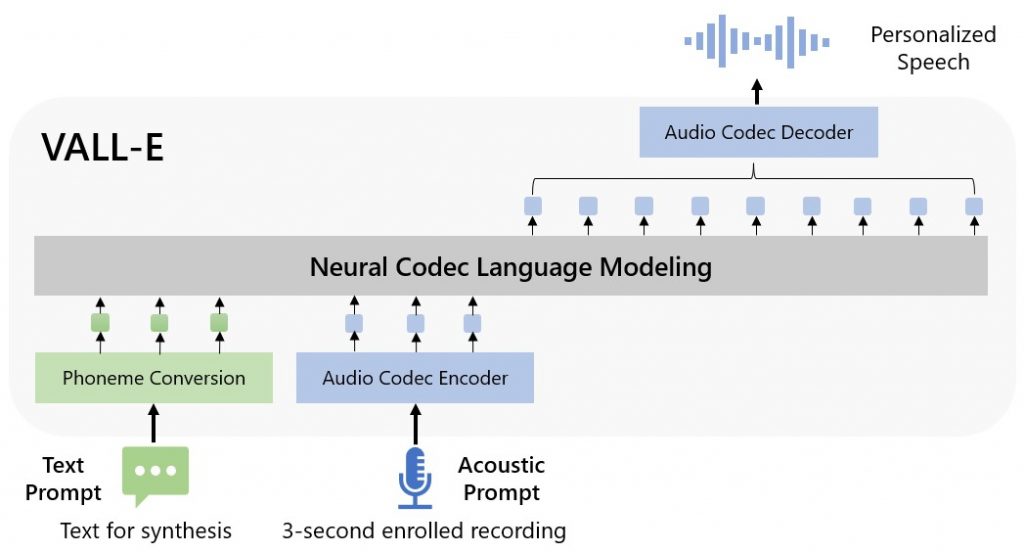 AI のしくみ。画像:VALL-E
AI のしくみ。画像:VALL-E
分析は、システムが十分に持っていることを示しました対話者の声を模倣する 3 秒間のクリップ。同時に、Vall-E は、自然な音声と音声の類似性という点で、今日の TTS システムよりもはるかに優れています。さらに、スピーカーの感情と音響環境 (元の録音が行われた部屋の音響特性の影響) を保存できます。
開発された発電システムはまだ閉鎖されていますパブリックアクセスですが、研究者はインターネット上のサイトでサンプルと完成した音声ファイルの例を公開しています。生成された音声のサンプルは品質が異なります。自然に聞こえるものもあれば、機械で生成されたものもあります。開発の著者は、さまざまなアクセントを含むさまざまな声でさらにトレーニングすることで、システムの品質が向上すると述べています。
人間の声のサンプル。オーディオ: VALL-E
外部ノイズを保持する生成された録音。オーディオ: VALL-E
研究者はまた、その可能性に注目しています。元の音声と同じ音声を生成すると、詐欺師に悪用される可能性があるため、新たなセキュリティ上の課題が生じます。彼らは、モデルが広く公開される前に、AI によって生成された記録を認識するシステムを開発する必要があると考えています。
続きを読む:
ローマのコンクリートの耐久性の秘密が明らかになりました:それは元に戻すことができます
遺伝学者は、人間の受胎年齢が25万年にわたってどのように変化したかを特定しました
太陽は最も強力なクラスのフラッシュで年を開けました