Мицрософт је увео вештачку интелигенцијуВАЛЛ-Е.генерисање гласовних снимака на основу
Истраживачи са Универзитета Корнелкористио ВАЛЛ-Е модел за анализу механизама генерисања говора. У свом раду, чији је препринт објављен на серверу арКсив, научници испитују неуронску мрежу обучену на основу 60.000 сати енглеског говора. Ово је стотине пута више од постојећих аналога.
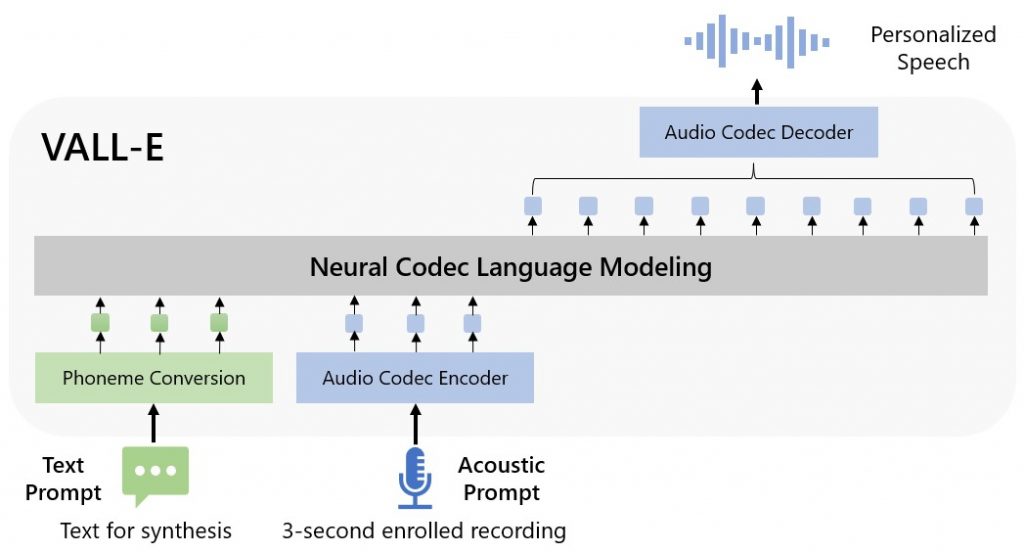 Како АИ ради. Слика: ВАЛЛ-Е
Како АИ ради. Слика: ВАЛЛ-Е
Анализа је показала да систем има довољноклип од три секунде за имитацију гласа саговорника. Истовремено, Валл-Е је далеко супериорнији од данашњег ТТС система у погледу природног звучања говора и сличности гласа. Осим тога, може да сачува емоције говорника и акустично окружење (утицај акустичких својстава просторије у којој је направљен оригинални снимак).
Развијени систем производње је и даље затворен зајавни приступ, али су истраживачи објавили примере узорака и готових гласовних датотека на сајту на Интернету. Узорци генерисаног говора се разликују по квалитету. Док неки звуче природно, други звуче машински. Аутори развоја напомињу да ће даља обука у различитим гласовима, укључујући и различите акценте, побољшати квалитет система.
Узорак људског гласа. Аудио: ВАЛЛ-Е
Генерисано снимање које чува спољну буку. Аудио: ВАЛЛ-Е
Истраживачи такође примећују да могућностгенерисање гласова који су идентични оригиналима ствара нове безбедносне изазове јер га преваранти могу искористити. Они верују да пре него што модел буде широко објављен у јавности, потребно је развити систем који ће препознати записе генерисане вештачком интелигенцијом.
Опширније:
Открива се тајна трајности римског бетона: може се обновити
Генетичари су утврдили како се старост зачећа код људи променила током 250.000 година
Сунце је отворило годину блеском најмоћније класе