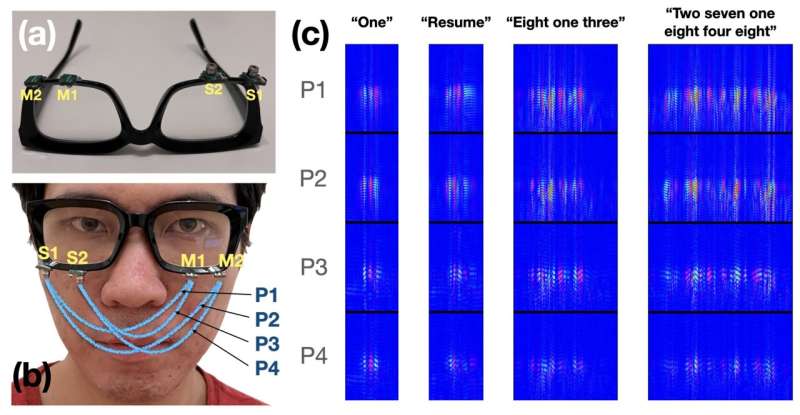
นักวิจัยจาก Cornell University ได้พัฒนาอินเทอร์เฟซ EchoSpeech สำหรับการจดจำคำพูดที่เงียบเสียง
แว่นตา EchoSpeech ติดตั้งไมโครโฟนคู่หนึ่งและลำโพงที่มีขนาดเล็กกว่ายางลบที่ปลายดินสอและไม่ใช้กล้อง อุปกรณ์จะส่งและรับคลื่นเสียงที่บ่งบอกถึงการเปลี่ยนแปลงไดนามิกของกล้ามเนื้อใบหน้าและปาก อัลกอริธึมการเรียนรู้เชิงลึกจะวิเคราะห์โปรไฟล์เสียงสะท้อนเหล่านี้แบบเรียลไทม์ด้วยความแม่นยำประมาณ 95%
 EchoSpeech ทำงานอย่างไร ภาพ: Ruidong Zhang และคณะ
EchoSpeech ทำงานอย่างไร ภาพ: Ruidong Zhang และคณะ
ข้อมูลที่ได้รับจะถูกส่งผ่านบลูทูธไปที่แบบเรียลไทม์บนสมาร์ทโฟน ประมวลผลและจัดเก็บไว้ในอุปกรณ์ นักพัฒนารายงานว่า EchoSpeech ใช้เวลาเพียงไม่กี่นาทีในการฝึกอบรมสำหรับผู้ใช้เฉพาะราย
สำหรับผู้ที่พูดไม่ได้ เทคโนโลยีการพูดเงียบนี้สามารถสังเคราะห์เสียงได้ดีเยี่ยม เธอสามารถให้เสียงแก่ผู้ป่วยได้
Ruidong Zhang ผู้ร่วมพัฒนา
เทคโนโลยีการรู้จำเสียงพูดแบบเงียบที่สุดจำกัดอยู่เพียงชุดคำสั่งที่กำหนดไว้ล่วงหน้าที่เลือกไว้ และกำหนดให้ผู้ใช้และคู่สนทนามองหรือสวมกล้อง สิ่งนี้ทำให้การใช้อุปกรณ์ดังกล่าวมีความซับซ้อนอย่างมาก นอกจากนี้ กระแสข้อมูลจำนวนมากจำเป็นต้องมีการประมวลผลในระบบคลาวด์ ซึ่งละเมิดความเป็นส่วนตัวของผู้ใช้
ในรูปแบบปัจจุบัน EchoSpeech สามารถทำได้ใช้สื่อสารกับผู้อื่นผ่านสมาร์ทโฟนในสถานที่ที่การพูดไม่สะดวกหรือไม่เหมาะสม เช่น ร้านอาหารที่มีเสียงดังหรือห้องสมุดที่เงียบสงบ อินเทอร์เฟซเสียงพูดแบบไม่มีเสียงสามารถจับคู่กับสไตลัสและซอฟต์แวร์การออกแบบ เช่น CAD ได้ ซึ่งช่วยลดความจำเป็นในการใช้แป้นพิมพ์และเมาส์ นักพัฒนากล่าวเพิ่มเติม
อ่านเพิ่มเติม:
นักวิทยาศาสตร์ค้นพบธรรมชาติของสัญญาณวิทยุประหลาดจากดาวเคราะห์ที่คล้ายกับโลก
รัศมีสีแดงสว่างขึ้นทั่วอิตาลี ตอนนี้ธรรมชาติของมันได้รับการอธิบายแล้ว
Webb ได้พบหลุมดำที่เก่าแก่ที่สุดในจักรวาล